目录
再聊进程创建
进程终止
进程等待
进程程序替换
再聊进程创建
初识进程创建
关于进程创建,这里只会说结论,在上面这篇文章中对进程创建进行了比较详细的阐述,而接下来要介绍的,都是基于上文说过的来展开的
一些较为重要的结论:
1、进程创建使用fork函数
fork无参数
哪个进程调用的fork,那么fork创建的就是哪个进程的子进程
fork的返回值
如果fork创建子进程成功,对于父进程来说就返回它创建的子进程的pid,对于子进程来说就返回0
如果fork创建子进程失败,对于父进程来说返回-1,子进程没有被创建,并且错误码被设置
2、fork之后父子进程代码共享
3、子进程PCB以父进程为模版
4、进程之间具有独立性,也就是进程之间不能相互影响
而在上文中的进程创建的最后,我提出了一个问题,就是为什么fork的返回值即等于0,又大于0,
实际上,由于子进程的进程地址空间和页表是基于父进程来开的,甚至在一开始的时候父子进程页表共享,所以变量的虚拟地址在父子进程中是相同的,而在子进程对变量进行写入时,会发生写时拷贝,这时子进程会重新开一张页表,这张页表也是拷贝的父进程的,但唯一不同的是这张页表会对这个被修改变量的虚拟地址所对应物理地址,此时虽然在上层看来好像父子进程的地址是一样的,但上层看到的其实是虚拟地址,而真实的物理地址实际上是两个变量,这一个结论在进程地址空间中进行了详细介绍,感兴趣可以去了解下
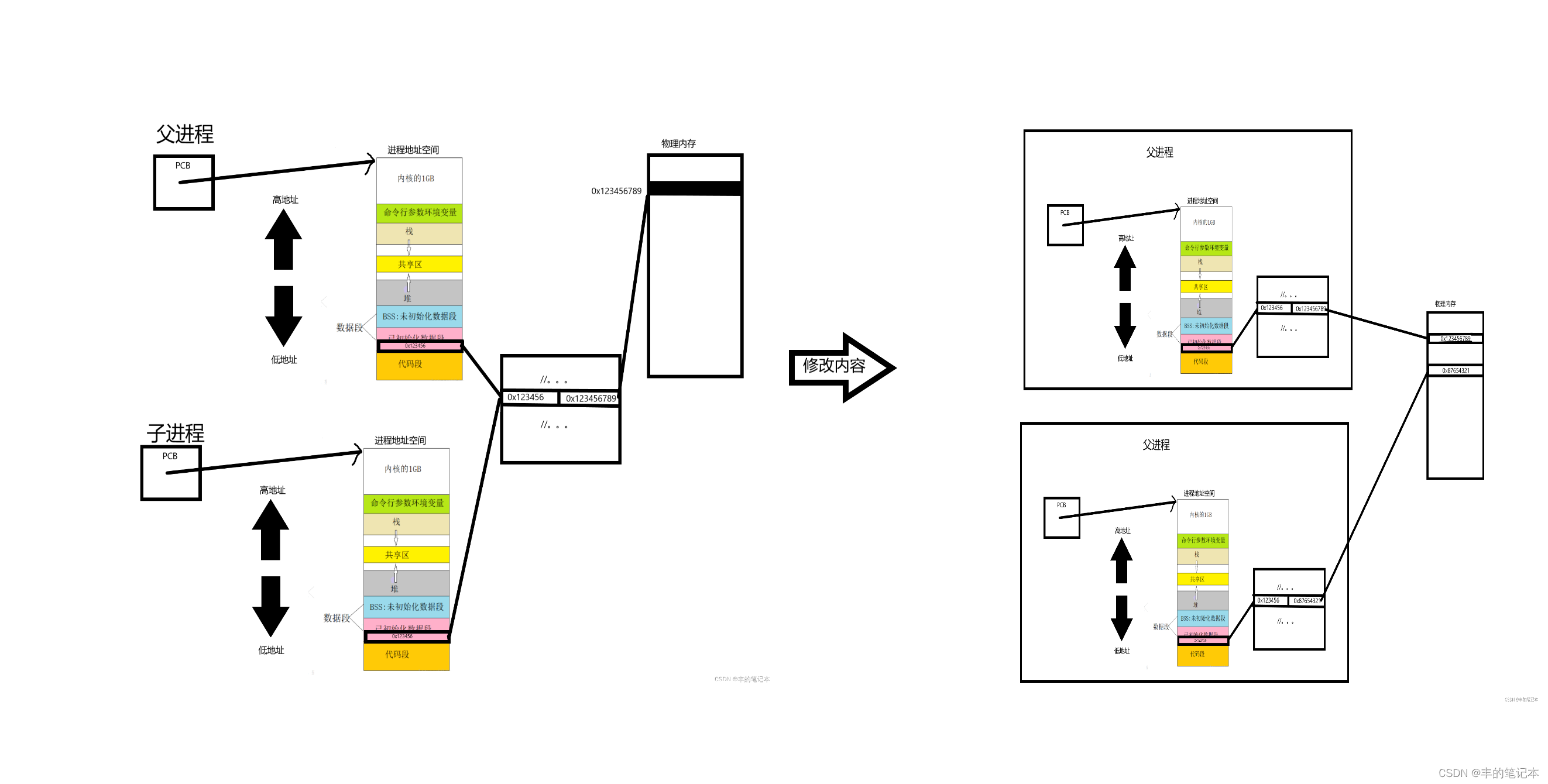
而接下来我们聊进程创建重点就是要聊写时拷贝
首先第一个问题是为什么需要有写时拷贝,难道父进程创建子进程的时候把自己的数据全部拷贝一份给子进程不行吗?
对于这一个问题,实际上子进程在被创建的时候不是一定要发生写入的,而就算要写入也不一定会全部数据进行写入,就算要全部写入也不一定是立马全部写入。如果父进程直接把自己的数据拷贝一份给子进程,那么创建子进程会变得比较慢,其次可能会导致内存资源的浪费
第二个问题,对于数据的写时拷贝为什么要拷贝呢?换句话来说难道我在写入的时候直接开辟好一个没有初始化的空间给子进程不行吗?
实际上,这个拷贝是非常有必要的,原因是进程对变量的写入不一定是直接覆盖式的,有可能的写入是对变量++,或者位运算等等,这些运算都是需要原始数据的,那么原始数据从哪来呢?肯定就只能从原来变量的值开始算起
上述两个问题,我回答了为什么要写时,以及为什么要拷贝
而接下来我们要聊的是怎么写时拷贝的问题
在刚开始子进程被创建的时候,父子进程共享的是同一个变量,这都好说,然后当我们进程对这个变量进行写入的时候子进程需要以共享的页表为模版重新开一张页表,然后改变这个变量所对应的物理地址,使得父子两个虽然从进程地址空间的角度来说是同一个变量,但实际上确是不同的物理地址,这些我们之前都说过。但现在有一个问题是,当父子当中某个进程对一个变量写入的时候,子进程怎么会知道自己需要重新开一张页表呢?换句话来说子进程怎么知道它写入的是与父进程共享的变量呢?
实际上,这里我们就需要引入一个关于页表的概念了
页表其实并不单单只有虚拟地址到物理地址的映射,页表当中还存储着一个权限位,这个权限有三个(r,w,x),这个权限位决定了变量所在的物理地址是否可读可写可执行,如下图
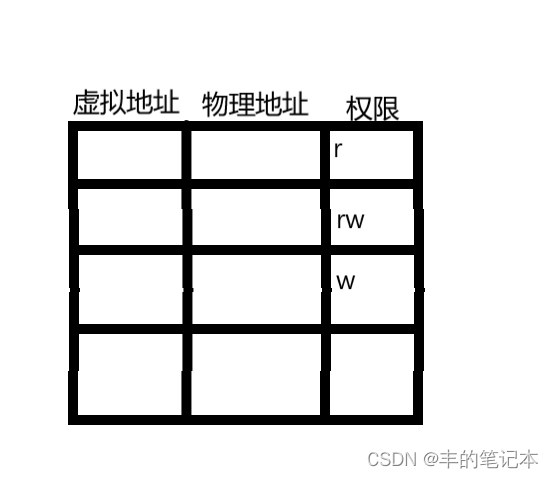
实际上,页表当中有一个权限位的概念,正是我们在写C语言的时候说字符串常量在常量区,常量区的数据不能修改的原因
当我们写一个对常量区的数据进行修改的代码时,这个代码会在页表转化物理地址时被拦截,原因就是因为常量区所有的地址在页表中都被设置为了只读的权限
实际上,我们所说的进程的写时拷贝也是基于这个页表当中的权限位
当父子进程对一个变量进行共享时,也就是子进程此时还没有生成自己的页表,这个变量在页表中的权限位会被修改为r,也就是只读。而当父子任意一个进程对这个变量进行修改时,子进程都需要生成自己的页表,但这个变量此时在页表中的权限是只读的,所以进程对变量的写入注定就会失败。而当写入失败了以后操作系统会跑来看一下失败的原因,并对你的这次错误进行种类判断,然后操作系统会发现这个变量是在一个本来可写的区域的,只是因为它的权限被设置为了只读所以才会报错的,于是操作系统就根据这一点判断了是子进程要写时拷贝了。此时才会发生子进程的写时拷贝,如下图
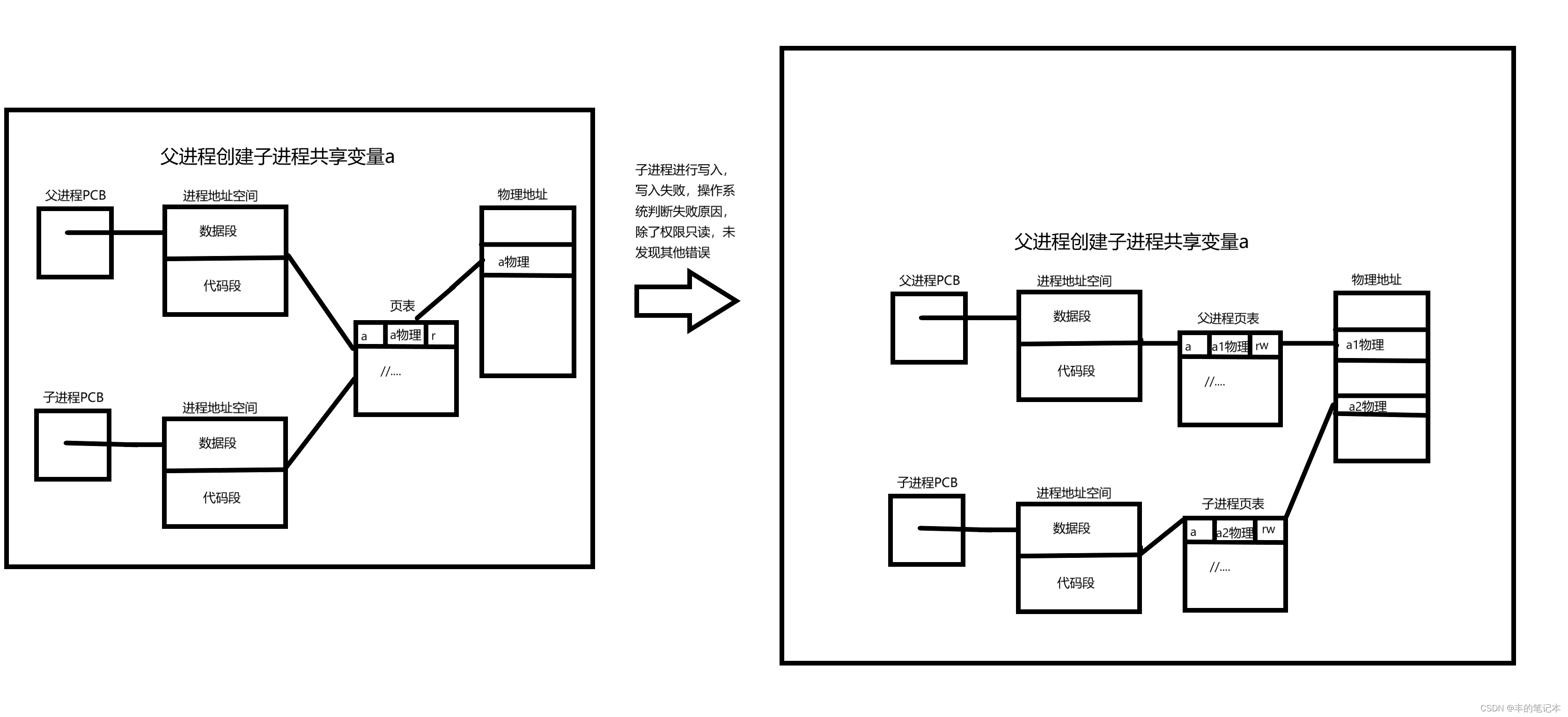
而上述我们只聊了第一个变量的写时拷贝,实际上父子俩共享的变量都被设置为了只读的,而当父子进程对一个变量进行写入时,只会对这个变量进行写时拷贝,其他变量都还是只读的。由于每个变量的权限位都是只读的,所以之后父子进程任意一方对任意一个只读变量进行写入时都会发生写时拷贝。当然,之后的写时拷贝由于子进程已经创建了一张页表,所以就不需要再次创建页表了
进程终止
在我们之前编写c语言代码的时候,程序可能会因为各种各样的原因导致终止,但归根到底程序终止分为以下3种情况:
1、代码运行完,结果正确
2、代码运行完,结果不正确
3、代码没有运行完
以上都好理解,接下来我们要聊得是关于进程的退出码
在你之前编写C语言代码的时候,如果有一个好的编程习惯,那么在main函数的结尾总会带上一个return 0,如下
#include <stdio.h>
int main()
{
printf("Hello,World\n");
return 0;
}要搞清楚这个return 0是什么意思,我们首先要搞懂你怎么判断你的代码执行的情况?
也就是说你的程序到底是进程终止的三种情况中的哪一个?
有人可能会说,这还不简单,我直接看看打印结果如何不就行了吗?
对于这一点,首先你的打印结果是给用户看的,而命令行看不到。其次,如果你的程序没有打印,你怎么知道代码运行结果呢?所以打印的方式没有普适性!
实际上,在main函数中最后的return语句,我们称之为进程的退出码
一般如果最后的退出码为0,表示代码运行完,结果正确
最后的退出码为非0,表示代码运行完,结果不正确
这个退出码最后是被bash拿到的,拿到了这个退出码,bash就知道了你这个进程的运行情况。
为了验证这个退出码最后是不是被bash拿到了,接下来我们需要使用echo $?指令,这个指令的意思是打印出bash最近执行一个进程的退出码,如下
//------------------------test---------------------------
#include <stdio.h>
int main()
{
return 0;
}
[yyf@VM-24-5-centos 24.06.09]$ ./test
[yyf@VM-24-5-centos 24.06.09]$ echo $?
0
可以看到,确实拿到了进程的退出码。当然,如果你把上述代码最后return的值进行修改,再次编译运行,会发现echo $?打印出来的就是你修改后的值。这一点可以自己去试试
实际上,之所以echo $?能打印出bash最近执行进程的退出码。是因为bash内部保存了这个退出码。
当然,接下来我们得聊聊为什么我们日常写代码的时候正常运行返回0,而运行完不正确是非0、
原因是因为对于一个进程来说,它如果正常运行,那么我们不需要知道它正常运行是什么原因。
而运行完不正确,不正确的原因可能有很多。而0只有一个,非0有很多个,所以就用0表示进程正常运行,非0表示代码运行完,结果不正确。
就好比我们平时参加各种各样考试的时候,如果你考的好,你跟你父母说,那你父母不会问你为什么考的好,这么问是比较奇怪的。如果你考的不好,你跟你父母说,那么你父母大概率是会问你为什么考的不好的。而此时你说出原因,比如肚子疼、没发挥好、没怎么学。而如果把你当成是进程,一个一个的原因就是一个个的退出码,就好比1表示肚子疼,2表示没发挥好....
但对于一个进程来说,它是否正常退出谁最关心呢?
首先就是操作系统,因为操作系统是进程的管理者
其次就是用户,因为这个程序是我写的,它运行失败没有达到我的预期,那么我需要对它进行修改,而怎么修改就依赖于退出原因
而一个进程的退出码对于计算机来说好识别,但对于人来说是不好识别的。就好比你父母问你考试为什么考好,你会回答一个数字吗?指定不会,父母需要的是具体的原因,在计算机中就是一个字符串。
而把一个退出码转化为字符串,有两种方式
1、C语言库函数strerror
2、自定义错误信息
我们先来聊聊strerror这个函数
strerror的功能是给我一个退出码,返回的是这个错误码所对应的错误信息,返回的类型是char*
strerror的参数为退出码
strerror的头文件是string.h
如下为demo代码:
#include <stdio.h>
#include <string.h>
int main()
{
for(int i = 0 ; i < 10 ; ++i)
{
printf("%d:%s\n",i,strerror(i));
}
return 0;
}这个demo代码实际上就是打印出0-9退出码所对应的退出信息
运行结果:
[yyf@VM-24-5-centos 24.06.09]$ ./test
0:Success
1:Operation not permitted
2:No such file or directory
3:No such process
4:Interrupted system call
5:Input/output error
6:No such device or address
7:Argument list too long
8:Exec format error
9:Bad file descriptor
实际上,当我们在命令行输入指令失败的时候,指令也是一个进程,也有自己的退出码。而命令行提示的错误信息实际上就是这个strerror返回的字符串
如下:
[yyf@VM-24-5-centos 24.06.09]$ ls xxxxx
ls: cannot access xxxxx: No such file or directory
[yyf@VM-24-5-centos 24.06.09]$ echo $?
2
可以发现,它提示的是No such file or directory,退出码为2,我们strerror中2所对应的退出信息与它提示的一样
当然,除了系统自己设置的退出码所对应的字符串含义之外,我们也可以自己设置,如下为自定义的demo代码
#include <stdio.h>
enum error
{
malloc_error=0,
open_file_error,
//...
};
char* errorToStr(int errNum)
{
if(errNum == malloc_error)
{
return "malloc error!";
}
else if(errNum == open_file_error)
{
return "open file error!";
}
else
{
return "unknown error!";
}
}
int main()
{
int code = malloc_error;
printf("%s\n",errorToStr(code));
return code;
}
运行结果:
[yyf@VM-24-5-centos 24.06.09]$ ./test
malloc error!
以上我们介绍了关于main函数的退出码的一系列内容,而接下来我们要聊的话题就是对于一个普通函数而言,我们需要知道这个函数的执行情况吗?
答案是肯定的,不管是什么函数,只要它执行了却失败了,我们都需要知道它的错误信息
以fopen为例,fopen这个函数的功能是打开一个文件,如果打开成功,返回这个文件的文件指针,如果打开失败,返回NULL
但是我们要思考一个问题,那就是fopen这个函数虽然可以通过它的返回值判断这个函数的运行到底是成功还是失败的,但对于用户来说最关心的其实还有什么呢?
答案是失败原因,也就是说fopen函数的返回值除了判断失败或者成功以外,不能辨别其他信息了,此时我们需要引入一个新的概念来查看一个函数运行失败的失败原因,也就是errno
实际上,fopen函数如果打开失败除了会返回空指针,错误码也会被设置,这里的错误码也就是errno
errno实际上就是一个整形变量,它的头文件是errno.h
如下为demo代码
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main()
{
FILE* fp = fopen("./xxxx","r");//以只读方式打开一个不存在的文件必然错误
printf("%d:%s\n",errno,strerror(errno));
return 0;
}
运行结果:
[yyf@VM-24-5-centos 24.06.09]$ ./test
2:No such file or directory
此时对于普通函数而言,我们即可以知道它的运行情况是成功还是失败,如果失败的话又可以获得它的失败原因。
当然errno的设置只会在库函数中发生,对于我们自己写的函数是不好对errno进行设置的
总结一下,在上述我们聊了进程终止的两种情况,代码运行完,结果正确或不正确
但上述聊的都建立在一个前提下,那就是代码运行完了,那么代码有没有可能在中途的时候因为一些原因导致终止了呢?实际上这是有可能的,如果代码写多了就会发现这种情况经常发生,比如除零错误,空指针访问。其实这些我们之前一般称为进程崩溃,也叫做异常终止
若一个进程发生异常终止表示这个进程的代码块没有运行完,终止的原因是因为当前进程收到了某种信号,而发信号我们一般用kill指令
kill的使用格式:kill -[信号编号] [进程pid]
kill一共有64种信号,但这里不细说,会在信号部分详细说,所有信号如下
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
如下为demo代码
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("I am process , pid : %d\n",getpid());
sleep(1);
}
return 0;
}
可以看到,上述代码是一个死循环,如下为如何给这个进程发送信号,导致它异常终止
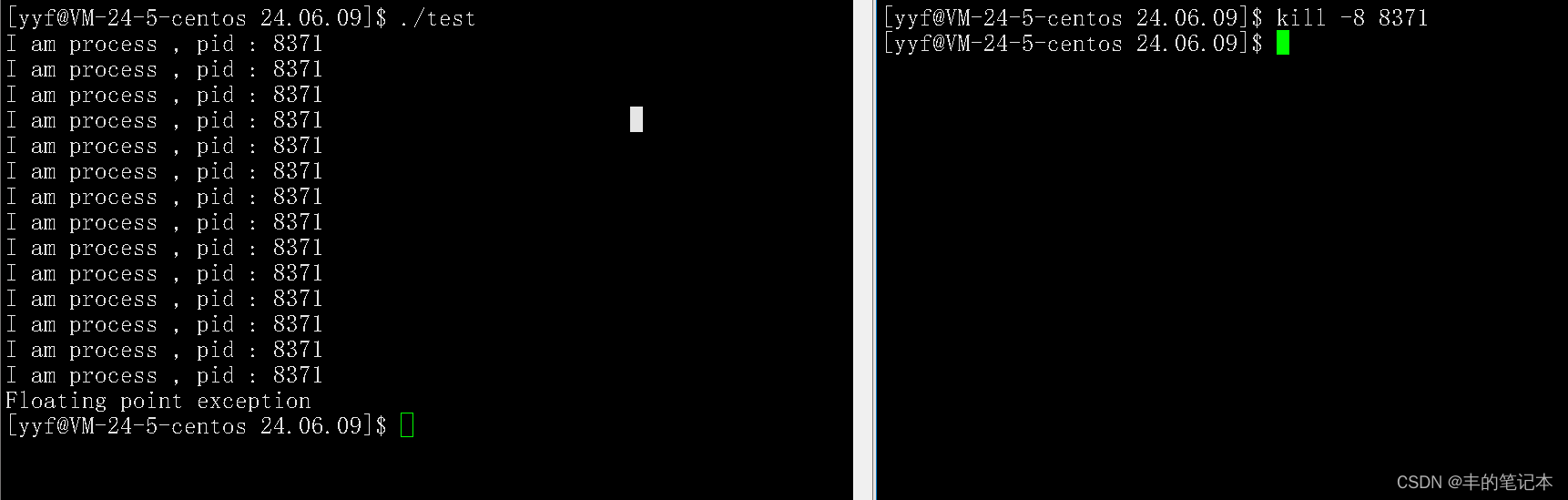
可以看到,当我给这个进程发送8号信号时,确实把这个进程终止了,并且在最后还提示除零错误。
我之前说进程终止就是操作系统给这个进程发送信号,接下来我们写一个本身就有除零错误的代码,如下为demo代码
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int a = 10;
printf("%d\n",a/0);
return 0;
}
运行结果:
[yyf@VM-24-5-centos 24.06.09]$ ./test
Floating point exception
可以看到,上述运行结果与我们自己给进程发送信号效果是一样的,说明这个进程终止确实是它收到了信号。
而接下来的问题是,代码运行完需要判断结果正不正确,为什么异常终止不用呢?
实际上,对于一个进程来说如果它发生了异常终止,那么它的退出码就没有意义了,就好比你父母问你考的怎么样,你说你作弊了,那么你的父母就不会管你分数如何而是问你为何作弊。
由于异常终止的进程本身就是错误的,所以也就不需要判断它运行结果是否正确,哪怕它真的达到你的预期,但这个代码也是有问题的
至此,我们进程退出的三个场景与其对应的表示方法和原因都说清楚了
退出码:前提是代码运行完了,判断结果正不正确
信号: 代码没有运行完,中途收到信号,进程终止
我们得出结论:只要一个进程的退出码和收到的信号可以拿到,那么这个进程的所有退出情况一览无余。因为你的进程不管怎么退出,都是要么代码运行完或者没有运行完,要么代码运行完结果正确或不正确。而我们说的退出码其实是一个整数,信号是带有编号的,也是一个整数,所以我们只需要有两个整形就能查到进程的退出情况(进程等待,这个结论会用到)
上述,关于进程终止的理论部分已经结束了,而接下来我们要了解的就是进程退出的具体操作
首先在Linux系统下,进程退出有两种方式
1、exit库函数
2、_exit系统调用
首先来介绍第一个,也就是exit库函数
exit的头文件是stdlib.h
exit是C语言库中的一个函数,这个函数的功能是使得调用exit函数的进程立即终止
exit的返回值void,exit有一个参数,这个参数就是进程退出后的退出码
如下为demo代码
#include <stdio.h>
#include <stdlib.h>
int main()
{
//1、输入退出码
int code = 0;
scanf("%d",&code);
//2、调用exit
exit(code);
return 0;
}
运行结果:
[yyf@VM-24-5-centos 24.06.09]$ ./test
1
[yyf@VM-24-5-centos 24.06.09]$ echo $?
1
[yyf@VM-24-5-centos 24.06.09]$ ./test
100
[yyf@VM-24-5-centos 24.06.09]$ echo $?
100
由上,可以看到参数确实是进程退出后的退出码
第二个方式是通过系统调用接口_exit
_exit的头文件为unistd.h
_exit的使用与exit几乎一模一样
如下为demo代码
#include <stdio.h>
#include <unistd.h>
int main()
{
//1、输入退出码
int code = 0;
scanf("%d",&code);
//2、调用_exit
_exit(code);
return 0;
}
运行结果:
[yyf@VM-24-5-centos 24.06.09]$ ./test
10
[yyf@VM-24-5-centos 24.06.09]$ echo $?
10
[yyf@VM-24-5-centos 24.06.09]$ ./test
5
[yyf@VM-24-5-centos 24.06.09]$ echo $?
5
上述,我们介绍了关于进程终止的两个函数,分别为exit和_exit,接下来要聊的话题是关于这两个函数的区别,接下来我们首先看一段demo代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
int code = 0;
scanf("%d",&code);
if(code > 10)
{
printf("退出码:%d",code);
_exit(code);
}
else
{
printf("退出码:%d",code);
exit(code);
}
return 0;
}上述代码首先输入退出码,退出码大于10调用_exit,退出码小于10调用exit,如下为运行结果
[yyf@VM-24-5-centos 24.06.09]$ ./test
100
[yyf@VM-24-5-centos 24.06.09]$ ./test
9
退出码:9[yyf@VM-24-5-centos 24.06.09]$ ./test
50
[yyf@VM-24-5-centos 24.06.09]$ ./test
5
退出码:5[yyf@VM-24-5-centos 24.06.09]$
我们发现调用exit的地方好像能打印出来,而调用_exit的地方打印不会生效
首先printf打印出来的数据首先是在缓冲区当中的,我们只能使用特殊方法,就比如加上/n或/r,才会把打印的数据从缓冲区当中刷新出来。而exit和_exit的区别就是exit会刷新缓冲区,而_exit不会刷新缓冲区
那么_exit有什么用呢?直接给个exit用就完事了,还比_exit好用
实际上终止一个进程只能由操作系统终止,这是因为进程本质上是内核级数据结构+可执行程序。而操作系统作为进程的管理者,所以它能终止进程.
而终止一个进程本质上其实是由用户写的代码决定什么时候终止进程的,操作系统并不知道什么时候该终止进程。而用户要访问内核空间只能使用系统调用,于是操作系统就提供了_exit这个系统调用接口。
而我们之前学习C语言的时候,一定听过一句话,叫做C语言具有可移植性。实际上,这句话的意思是我们用C语言写出来的代码,不管是在Linux还是在Windows上都可以正常运行的,它是怎么做到的呢?
首先,如果要访问操作系统的内核空间,不管是Linux还是Windows,它们虽然都可以进行访问,但所使用的系统调用接口是不同的,而C语言库把这些系统调用接口进行封装,形成一套不管什么操作系统都可兼容的接口。就比如说库函数中的exit接口,它在Linux下的C库实现一定是封装了_exit这个接口,而在Windows下用的就是Windows自己的进程终止的系统调用接口。如下图
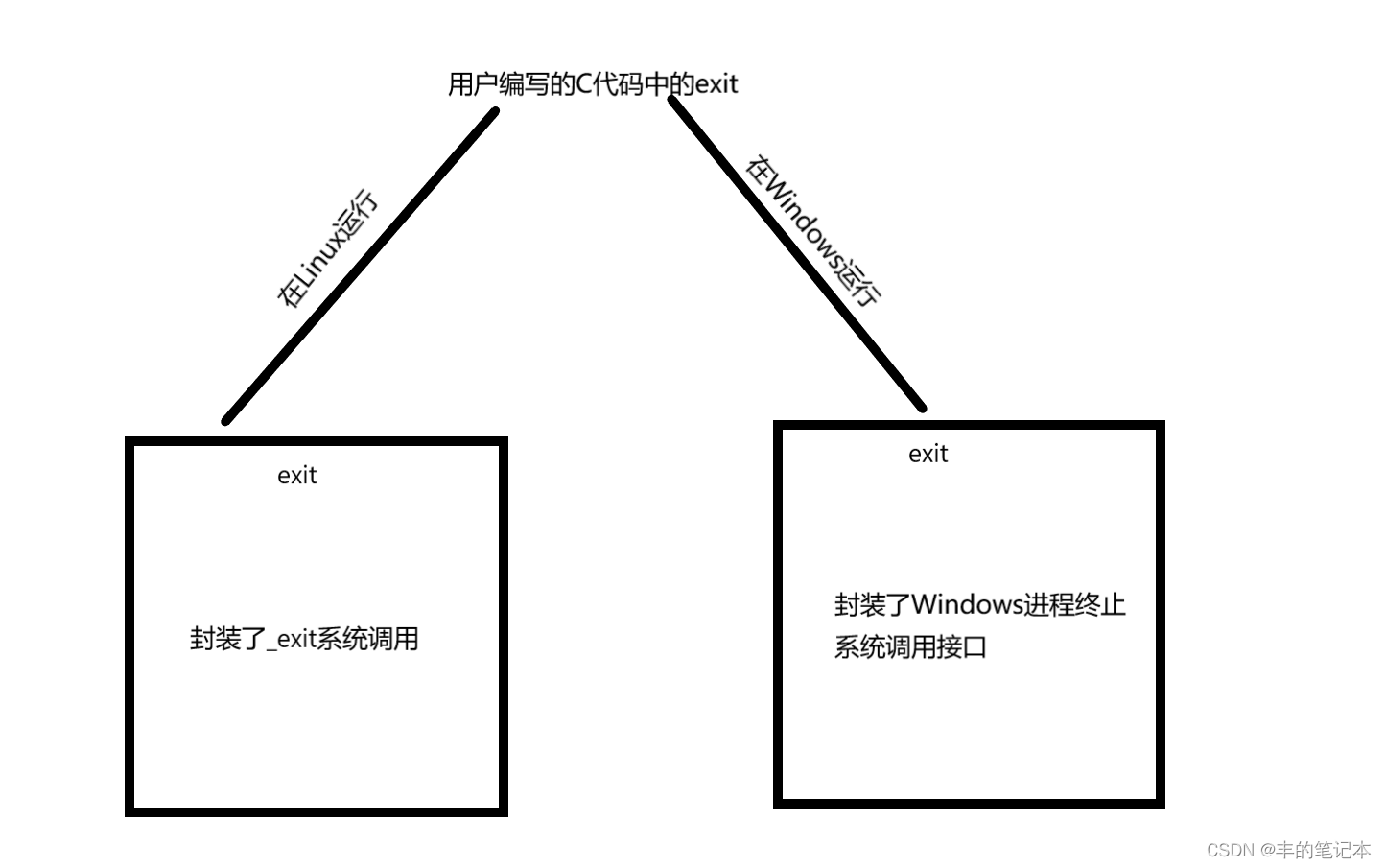
而上述,我们聊的都是exit这个C库函数,但实际上库函数中只要与系统强相关的函数都封装了系统调用,比如printf。
由此,我们也可以知道,其实C语言所谓的具有可移植性,是因为不同平台的底层的差异化通过库封装的方式屏蔽掉了
进程等待
为什么要有进程等待?
实际上在我们之前的博客介绍过一种进程:僵尸进程
僵尸进程是指这个进程退出了,但它的PCB当中还保存着退出信息
实际上,一个僵尸进程如果没有进程来回收它的资源,那么这个僵尸进程就会一直在内存中,从而导致内存泄漏,所以我们所谓的进程等待一方面是为了解决这个问题,这也是必须解决的问题。
其次,父进程创建子进程大多是为了让子进程执行一段代码的,既然子进程需要执行一段代码,那子进程肯定有自己的执行情况,而我父进程有可能需要拿到它的执行情况。既然要父进程要拿到子进程的执行情况,那么自然而然父进程就需要等待子进程结束后再拿到它的执行情况。实际上执行情况指的就是我们进程退出时讲的退出码和退出信号
所以一句话总结一下为什么需要进程等待:
1、防止发生内存泄漏(必须)
2、父进程能拿到子进程退出信息(可选)
接下来让我介绍一下父进程如何等待子进程
1、系统调用-wait
2、系统调用-waitpid
首先,先介绍wait函数
wait的头文件:sys/types.h 和 sys/wait.h
wait的参数(status):类型是int*,这个参数是输出型参数,wait如果成功,它里面会保存退出的进程的退出信息!wait如果失败,参数的值不变
wait的返回值:类型是pid_t,如果父进程等待子进程成功,返回子进程的pid,如果父进程等待子进程失败,返回-1
wait的功能:使当前进程阻塞等待任一子进程退出,回收子进程资源,并获得等待的子进程的退出信息保存在status参数中
如下为demo代码:
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
printf("I am child , pid:%d , ppid:%d\n",getpid(),getppid());
cnt--;
sleep(1);
}
printf("child exit\n");
exit(1);
}
//父进程
sleep(10);
printf("father is waiting\n");
pid_t rid = wait(NULL);
printf("father wait success!\n");
sleep(3);
return 0;
}
上述这段代码
0-5秒时,父子进程是S状态。
5-10秒时,父进程是S状态,子进程是Z状态。
10-13秒时,父进程是S状态,子进程退出完毕
感兴趣可以自己去试试,文章中不太好演示
接下来介绍一下另一个系统调用接口:waitpid
waitpid的头文件:sys/types.h和sys/wait.h
waitpid的参数有三个:分别为pid、status、options
首先pid的类型是pid_t,pid如果为-1,表示的是等待任一子进程。pid如果大于0,表示的是等待pid与进程ID相同的子进程
status:这是一个输出型参数,用法与wait那个唯一参数一模一样
option:设置等待模式(阻塞/非阻塞)后面详细介绍,现在用0
waitpid的返回值是等待的子进程的pid
waitpid的功能是以(阻塞/非阻塞)方式等待子进程退出,然后回收子进程的资源,并获得它的退出信息保存在status参数中
如下为demo代码:
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
printf("I am child , pid:%d , ppid:%d\n",getpid(),getppid());
cnt--;
sleep(1);
}
printf("child exit\n");
exit(1);
}
//父进程
sleep(10);
printf("father is waiting\n");
int status = 0;
pid_t rid = waitpid(id,&status,0);
printf("father wait success!wait_process_id:%d,status:%d\n",rid,status);
sleep(3);
return 0;
}
运行结果:
I am child , pid:29623 , ppid:29622
I am child , pid:29623 , ppid:29622
I am child , pid:29623 , ppid:29622
I am child , pid:29623 , ppid:29622
I am child , pid:29623 , ppid:29622
child exit
father is waiting
father wait success!wait_process_id:29623,status:256
可以看到waitpid的返回值其实就是你传过去的第一个参数,也就是你指定进程ID的进程,这与wait是一样的。
而在上述代码中,我用status变量接收了子进程的退出信息,而子进程退出时的退出码我设置为了1,为什么它打印出来是256呢?
实际上虽然status参数从表面上看是一个整形变量,但实际上status有自己的格式。
因为退出信息需要包含了两个,一个是退出码一个是退出信号。
所以status有自己的格式,这个格式使他能够用一个整形变量表示两个信息
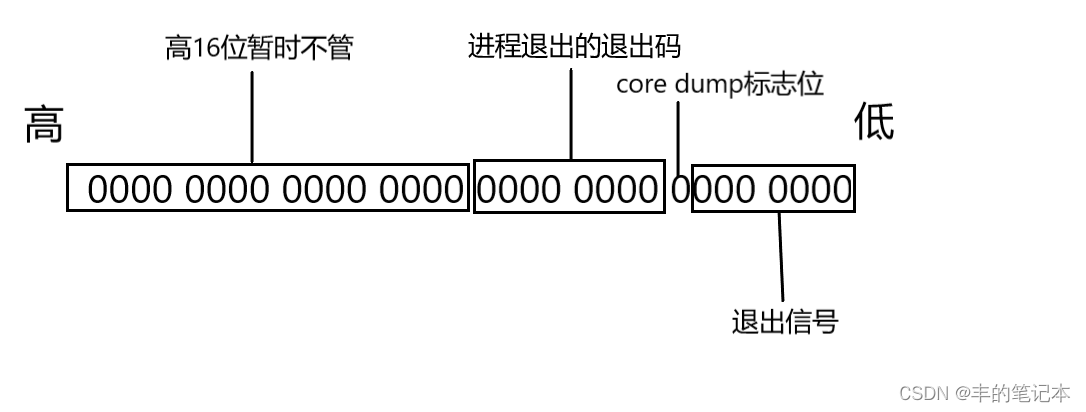
接下来就让我们详细看看status这个参数的格式
首先,status是一个整形变量,它一共拥有32个比特位
对于高16位,先不管,接下来主要讨论低16位
对于低16位,1-7位表示的是进程退出时收到的退出信号
而9-16位,表示的是进程退出时的退出码
第8位,表示的是core dump标志位,对于这一位我们暂时不管,信号部分会相信说明
所以status的格式如图所示
而根据这种格式,我们就能用一个status变量来表示两个退出时的信息
所以,在我们上述代码中为什么我设置进程退出码为1,而打印出来是256,原因是因为它的status变量的二进制如下所示:
status = 0000 0000 0000 0000 0000 0001 0000 0000
而这个数字转化为十进制就是256
所以,如果我们需要获得退出码或者退出信号时,就需要通过位操作的方式获取
进程的退出信号编号 = status & 0x7F
0x7F = 0000 0000 0000 0000 0000 0000 0111 1111
进程的退出码 = ( status >> 8 ) & 0x7F
而根据这两个,我们就可以写一个demo代码用来验证是否可以得出子进程的退出码和退出信号
如下为demo代码
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//子进程
int exit_code = 0;//子进程退出码
scanf("%d",&exit_code);
printf("I am child , pid:%d , ppid:%d\n",getpid(),getppid());
if(exit_code > 50)
{
exit(exit_code);
}
else
{
int a = 10;
a/=0;//故意写的除零错误
}
}
//父进程
int status = 0;
pid_t rid = waitpid(id,&status,0);
printf("wait success! pid:%d ,
return val:%d , status:%d ,
exit code:%d , exit signal:%d\n",
getpid(),rid,status,(status>>8)&0x7F,status&0x7F);
return 0;
}
上述代码就是由用户自己输入子进程的退出码
如果设置的退出码小于50,那么就会发生除零错误,按理来说就会收到8号信号
如果设置的退出码大于50,那么子进程立马退出
下面是运行结果
[yyf@VM-24-5-centos 24.06.10]$ ./test
100
I am child , pid:16597 , ppid:16596
wait success! pid:16596 , return val:16597 , status:25600 , exit code:100 , exit signal:0
[yyf@VM-24-5-centos 24.06.10]$ ./test
20
I am child , pid:16647 , ppid:16646
wait success! pid:16646 , return val:16647 , status:8 , exit code:0 , exit signal:8
可以看到,结果与我们预想的相同
当然,除了上述位操作的方式来获取退出信息以外,Linux还提供了两个宏用来获取退出信息
1、WIFEXITED(status):若status的0-7位为全零,则返回真,反之为假
换句话来说也就是判断一个进程有没有收到退出信号,如果收到则为假,反之则为真
2、WEXITSTATUS(status):若WIFEXITED非零,提取子进程的退出码。反之不提取
上述对于waitpid的使用以及进程等待的概念,我们已经了解的差不多了,最后一个点就是关于阻塞等待和非阻塞等待的区别
阻塞等待:父进程等待子进程时,父进程就在那一直等什么也不做,直到子进程退出
非阻塞等待:父进程不会一直等待子进程直到结束,而是在调用等待的地方去查看一下子进程是否退出,然后立马返回,如果子进程已经退出了返回值就是子进程的pid,如果等待成功但子进程没有退出则返回0,如果等待失败返回小于零的数
实际上,阻塞等待在某些场景中不一定那么好,原因是因为父进程在等待子进程时什么都不能做,只能在那干等着,从而导致资源浪费,特别是当子进程迟迟不退出的时候,浪费更为明显
而非阻塞等待,父进程只需要定期去看看子进程的退出情况即可,在其他的时候父进程可以去执行自己的工作
在Linux中的系统调用waitpid的第三个参数可以进行设置阻塞还是非阻塞
如果waitpid的第三个参数是0,那么就是阻塞等待
如果waitpid的第三个参数是1,那么就是非阻塞等待
对于阻塞等待,我们上文一直用的都是,不过多介绍了
如下demo代码为父进程非阻塞等待:
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
sleep(1);
cnt--;
}
exit(5);
}
//父进程
int status = 0;
while(1)
{
pid_t rid = waitpid(id,&status,1);
if(rid == 0)
{
//子进程没退出
printf("father is running\n");
sleep(1);
}
else
{
//子进程退出
printf("father end!\n");
break;
}
}
return 0;
}
father is running
father is running
father is running
father is running
father is running
father is running
father end!
可以看到,当子进程没有退出时,父进程一直在运行其他的代码,而不是一直在那等
而这其实也是基于非阻塞的轮询访问
进程程序替换
在我们之前的理解中,一个进程包括PCB和可执行程序,并且这个进程只能执行自己的可执行程序,但如果我们要让这个进程执行其他的可执行程序的代码的话,可以做到吗?
实际上,我既然说了就肯定可以,这也是进程程序替换所实现的功能:让一个进程执行其他的程序的代码
首先,我们先介绍进程程序替换的原理,如下图
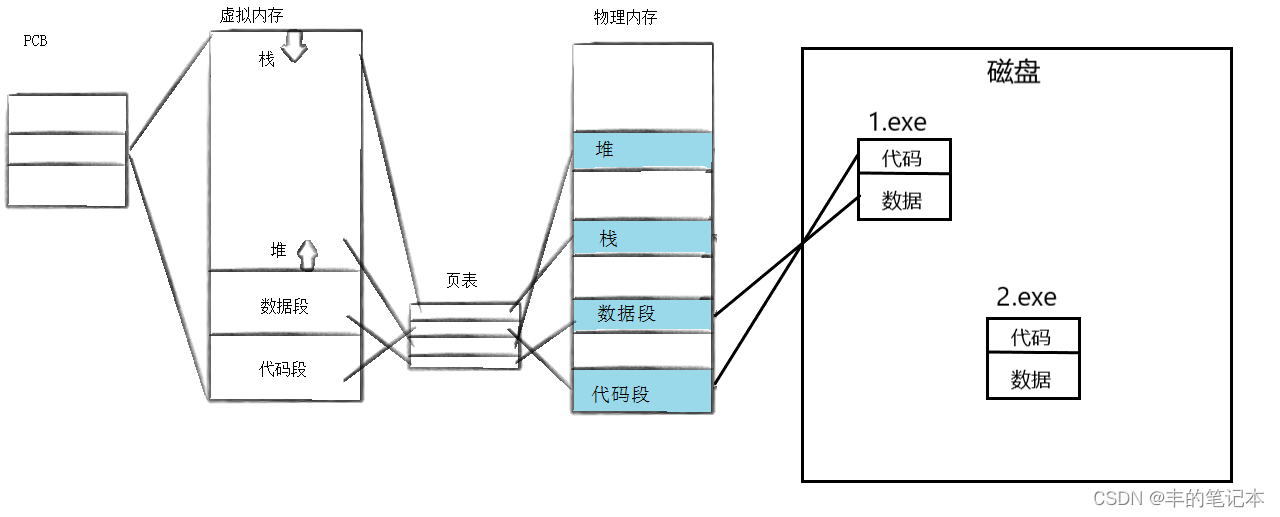
在还没有替换之前呢,这个进程的可执行程序是1.exe,而1.exe的数据和代码都分别放在数据段和代码段。
而现在如果我们需要把1.exe替换成为2.exe那么应该怎么做呢?
首先就是把2.exe的代码和数据覆盖在原来1.exe代码和数据所在的物理内存上,然后对于栈区和堆区你该初始化就初始化,该释放就释放,然后对于页表你修改一下,然后对于虚拟内存中区域的划分你该调整就调整一下。而这些工作全部做完以后也就如下图所示
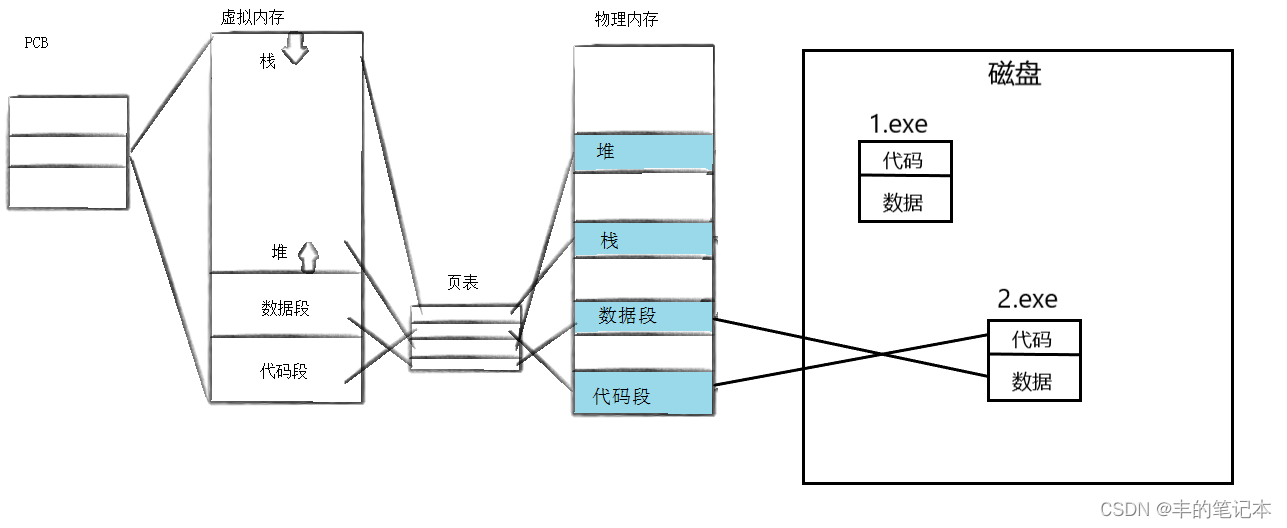
实际上,上面的工作,不管是覆盖代码和数据也好,修改页表和虚拟内存也好,这本质上都是在原来的进程的基础上的,这个页表和虚拟内存从来没有释放过,而这个PCB中的大部分属性(pid等)都没有变化,所以这个进程还是原来的进程,只是这个进程的可执行程序从1.exe替换为了2.exe。换句话来说也就是2.exe借用了原来1.exe进程的壳子罢了
而CPU在调用你这个进程的时候可不会管你的可执行程序是什么,它完成自己的工作即可
这也就是进程程序替换的原理
而接下来我们就要聊聊关于Linux下进程程序替换的函数接口:
首先要介绍的是execl这个函数,这个函数与我们之前所遇到的有些不同,如下为man手册中它的声明
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
这个函数的头文件是unistd.h
它的第一个参数path:就是你要执行的程序所在的路径
它的第二个参数arg及其之后的参数:这个arg是一个可变参数,换句话来说也就是arg可以传多个参数给它,实际上对于这个参数我们之前肯定用过,例如printf,printf的参数就是可变参数,所以我们可以传多个参数
arg实际上表示的是你想怎么执行这个程序,比如带什么选项啊等等,我们在用的时候直接命令行怎么写我们怎么传,原来的空格为分割改为以逗号为分割,如下
命令行:ls -a -l -n
arg参数:"ls","-a","-l","-n"
但需要注意,arg参数最后一定要以NULL结尾
而关于execl返回值后面一点再说
如下为demo代码
#include <stdio.h>
#include <unistd.h>
int main()
{
execl("/usr/bin/ls","ls",NULL);
printf("execl success!\n");
return 0;
}
运行结果:
[yyf@VM-24-5-centos 24.06.11]$ ls
makefile test test.c
[yyf@VM-24-5-centos 24.06.11]$ ./test
makefile test test.c
此时就把我们得程序替换成了指令ls
但我们可以观察到,上述的代码execl程序替换之后,还有一行printf打印,但我们的程序执行时并没有打印,由此我们得出结论:程序替换一旦成功,execl后续的代码不再执行,因为程序已经被替换掉了
实际上,execl对于它的返回值来说,只有出错返回,没有成功返回,因为如果execl替换成功了!那么程序就已经被替换掉了,它的返回值也就没有意义了
所以对于程序替换函数,我们在它之后的代码不用进行判断直接错误处理即可,如下为demo代码
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
execl("usr/bin/ls","ls",NULL);
printf("execl fail!\n");
exit(1);
}
对于这段代码,我故意把execl的path参数给写错,导致找不到这个ls程序,所以程序替换失败,之后会打印execl fail!然后退出码为1,接下来看运行结果
[yyf@VM-24-5-centos 24.06.11]$ ./test
execl fail!
[yyf@VM-24-5-centos 24.06.11]$ echo $?
1
而接下来我们要验证的是之前讲原理部分说的:进程程序替换只是替换了可执行程序,进程没有被替换,如下为demo代码
//----------------------test1.c-------------------
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("I am test1,pid:%d\n",getpid());
execl("./test2","./test2",NULL);
printf("execl fail!\n");
exit(1);
}
//----------------------test2.c--------------------
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("I am test2,pid:%d\n",getpid());
return 0;
}
有两个程序test1和test2,然后我运行test1,test1首先打印自己的pid,然后替换为test2,接着test2也会打印自己的pid,我们看看两个pid是否相同
如下为运行结果:
I am test1,pid:26237
I am test2,pid:26237
在上面我们讲了execl这个接口,实际上exec系列的替换接口有很多,如下是man手册中查到的
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg,
..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],
char *const envp[]);int execve(const char *filename, char *const argv[],
char *const envp[]);
接下来介绍execlp这个接口
int execlp(const char *file, const char *arg, ...);
首先,对于后面的arg,与我们之前讲的execl是一样的
不同的是execlp的第一个参数是file,也就是文件名
而execl的第一个参数是path,也就是文件路径
实际上在函数名加上p的所有exec系列接口都有如下特性:
p是PATH的缩写,也就是你不需要告诉系统这个程序的路径在哪里,只需要告诉系统这个程序的名字,系统会自动在环境变量中查找,而使用的其他方面与execl相同
如下为demo代码:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
execlp("ls","ls","-a","-l",NULL);//第一个参数不需要带路径,自动去环境变量找
printf("exec fail!\n");
exit(1);
}
如下为运行结果:
[yyf@VM-24-5-centos 24.06.11]$ ls -a -l
total 28
drwxrwxr-x 2 yyf yyf 4096 Jun 11 17:27 .
drwxrwxr-x 13 yyf yyf 4096 Jun 11 15:06 ..
-rw-rw-r-- 1 yyf yyf 67 Jun 11 17:25 makefile
-rwxrwxr-x 1 yyf yyf 8456 Jun 11 17:27 test
-rw-rw-r-- 1 yyf yyf 393 Jun 11 17:27 test.c
[yyf@VM-24-5-centos 24.06.11]$ ./test
total 28
drwxrwxr-x 2 yyf yyf 4096 Jun 11 17:27 .
drwxrwxr-x 13 yyf yyf 4096 Jun 11 15:06 ..
-rw-rw-r-- 1 yyf yyf 67 Jun 11 17:25 makefile
-rwxrwxr-x 1 yyf yyf 8456 Jun 11 17:27 test
-rw-rw-r-- 1 yyf yyf 393 Jun 11 17:27 test.c
当然,虽然说exec系列中带p的接口都不需要传路径,但第一个参数也可以是路径。
接下来聊得是exec系列中带v的接口
int execv(const char *path, char *const argv[]);
对于这类的接口,参数中都有一个argv参数,这个参数其实我们以前遇到过,就是在讲命令行参数时引入过这个argv的参数,实际上argv是一个指针数组,里面的每一个元素都存储着一个字符串,你想怎么执行通过传argv参数即可,argv以NULL作为结束标志
如下demo代码
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
char* const argv[] = {"ls","-a","-l","-n",NULL};
execv("/usr/bin/ls",argv);
printf("exec fail!\n");
exit(1);
}
运行结果:
total 28
drwxrwxr-x 2 1001 1001 4096 Jun 11 18:37 .
drwxrwxr-x 13 1001 1001 4096 Jun 11 15:06 ..
-rw-rw-r-- 1 1001 1001 67 Jun 11 17:25 makefile
-rwxrwxr-x 1 1001 1001 8456 Jun 11 18:37 test
-rw-rw-r-- 1 1001 1001 379 Jun 11 18:37 test.c
实际上exec系列中带l和带v的区别就是一个是以list列表方式进行传参,一个是以vector也就是数组形式进行传参,而列表暂时就看成是可变参数的意思
int execvp(const char *file, char *const argv[]);
而execvp就相当于不需要你指定路径,你给个文件名,系统自动去环境变量中找,并且传参是用数组来传。
前面讲了exec中带v、l、p
最后关于exec系列中还有一个是带e的,例如execve,execvpe,execle
e实际上是enviorn的缩写,表示的是环境变量。
int execle(const char *path, const char *arg,
..., char * const envp[]);
也就是说你在进行exec替换的时候可以给替换的进程进行自定义环境变量表,而没有带e的进程程序替换函数都是默认把自己的环境变量运用到新的程序中
实际上envp这个参数就是用来接收环境变量表的
如下为demo代码
//-------------------test.c---------------------
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main(int argc,const char* argv[],const char* env[])
{
for(int i = 0 ; env[i] ; ++i)
{
printf("%d:%s\n",i,env[i]);
}
return 0;
}
//-------------------demo.c-----------------------
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
char*const env[] = {"myenv=aaaaaaaaaaaaaaaaaaaaa",NULL};
execle("./test","./test",NULL,env);
printf("exec fail!\n");
exit(1);
}
上述demo.c中先自定义了一个环境变量表,这个表里面只有一个环境变量就是myenv,然后进行程序替换,而test.c代码就是打印自己的环境变量表。
如果带e的exec系列接口可以自定义环境变量表,那么上述代码的运行结果就应该是只打印了一行,也就是myenv这个环境变量
如下为运行结果:
[yyf@VM-24-5-centos 24.06.11]$ ./demo
0:myenv=aaaaaaaaaaaaaaaaaaaaa
可以看到,结果与其他相符,至此exec系列中带e、p、l、v的含义是什么都已经说明完毕,而那exec系列接口无外乎就是这4个进行组合,就比如execve就是指的用数组形式传执行方法,并且可以自定义环境变量表
实际上,如果我们用man手册查询exec系列接口,会发现只有一个execve是在2号手册,也就是系统调用的手册,其他的所有exec系列接口都是在3号手册,也就是库函数
实际上所谓进程程序替换也是对内核数据的一种修改,而对系统内部进行修改就一定要通过操作系统来修改,但操作系统并不信任用户,所以它会给用户系统调用接口来访问内核。而实际上操作系统对于进程程序替换只提供了一个系统调用,也就是execve,而其他的exec系列接口都是对这个系统调用进行封装实现的。
最后补充一个点,所谓的进程程序替换与语言层面其实已经没有关系了,换句话来说只要是在Linux系统上能跑的语言,那么就能通过进程程序替换把这个语言所生成的可执行程序进行替换。因为无论什么语言编写的程序,只要运行起来,它就是一个进程。






![[电子电路学]电路分析基本概念1](https://img-blog.csdnimg.cn/direct/d62ffa0f718145248c1e2e57131bd65f.png)